This page collects some notes about different Operating System approaches.
Most of the information gathered here is from the course Advanced Operating Systems.
Some information is from Operating System. And other Wikipedia pages.
The book Modern Operating Systems by Andrew S. Tanenbaum is also a very good resource I’m using for learning about Operating Systems.
Overview of Kernels
| Kernel | Type | Programming Language | Notes |
|---|---|---|---|
| SPIN | Microkernel (Mach-like) | Modula-3 | Special approach. |
| Linux | Monolithic (modular) | C, Assembly | Loadable kernel modules allow loading extensions (drivers) at runtime. |
| XNU | Hybrid | C, C++ | Kernel of OS X. Mach-3.0 and FreeBSD combined. |
| BSD | Monolithic | C | FreeBSD, OpenBSD, NetBSD… |
| Mach | Microkernel | C? | One of the earlyest mikrokernel. Not all mach versions are mikrokernels. |
| Windows | Hybrid | C, C++, Assembly | Win NT: Hybrid, Win 9x and earlyer: Mololithic. |
| FreeRTOS | Microkernel (RTOS) | C, Assembly | Real Time OS. Mainly for embedded systems. |
| UNIX | Monolithic | C, Assembly | Original: AT&T Unix. |
| L3 | Microkernel | ELAN | Predecessor of L4. |
| Barrelfish | “Multikernel” | C | Special aproach. |
| Mac OS 9 | Microkernel (Nanokernel) | ? | Legacy |
| QNX | Microkernel (RTOS) | ? | Unix-Like (POSIX), Qt supported. |
| VxWorks | Monolithic (RTOS) | ? | |
| Spring | Microkernel | independent (CORBA IDL) | Solaris emulation, OOP design, doors … |
Other OS’s:
Sharing Resources
One of the most important task of an OS is to share (hardware) resources. There are two posibilities how resources can be shared.
- time sharing: i.e CPU, Printer
- space sharing: i.e RAM, Hard Disc
Exokernel
Allocating resources to library OS’s:
- space (memory)
- time (CPU)
Library OS’s can ‘download’ code into the kernel. A security management mechanism checks if it is allowed by th library OS.
Memory (TLB)
TLB: Translation Lookaside Buffer. Software-TLB is snapshot for the TLB for switching the library OS’s.
CPU-Scheduling
- Linear vector of “time slots”
- Each library-OS marks the time slots for own use
- If OS takes more time than allowed in a time slot it gets less time in the next time slot (penalty)
- Strand as abstraction of threads
Revoction of Resources
- Exokernel tells the library OS which resources are revoked (repossesion vector)
L3
L3 strikes against microkernel
- Kernel-User switches (boarder crossing cost)
- Address space switches (Protected Procedures Calls for Cross Protection domain calls)
- Thread switches + IPC (Kernel mediation for PPC)
- Memory effects (locality loss)
Thesis of L3 for OS structuring
- Minimal abstractions in microkernel
- Microkernels are processor specific in implementation => non-portable
- Right set of microkernel abstractions and processor-specific implementation => efficient processor independent abstractions at higher levels
L3 is faster than Mach (Microkernel).
Virtualization
Hypervisor: Operation system of operation systems (VMM: Virtal Machine Monitor).
Native Hypervisor (bare metal)
Hypervisor runs directly on hardware. Guest OS’s running inside the hypervisor.
Hosted Hypervisors
Run on top of a Host OS (as an application process). Guest OS’s running inside the hypervisor.
- VMWare Workstation
- VirtualBox
Full virtualization
- Guest OS’s are not touched (unchanged binaries)
- They are running as user process in host OS
- Privileged instructios in guest OS’s trigger trap in hypervisor (trap and emulate)
- i.e. VMWare
Para Virtualization
- Guest OS is modified to run on an an hypervisor
- A very small percentage of the guest OS code needs to be changed
- i.e. Xen
Overview
Virtualize hardware:
- memory hierarchy
- CPU
- Devices
Memory Virtualization
Not virtualized:
Page Table (PT) maps Virtual Page Numbers (VPN) of processes to Physical Page Number (PPN).
Virtualized:
Guest OS translates Virtual Page Number (VPN) to Physical Page Number (PPN) with Page Table (PT). Hypervisor then translates Physical Page Number (PPN) to Machine Page Number (MPN) with Shadow Page Table (S-PT).
CPU Virtualization
Events that happen in a task of the Guest OS need to be delivered to the Guest OS by the Hypervisor.
An event can be:
- External Interrupt (HW Interrupt)
- Exception (HW- and SW-Exception)
- Page Fault
- Syscall
The occured events are delivered to the Guest OS wrapped in a SW-Interrupt by the Hypervisor.
Communication from the Guest OS to the CPU hapens generally through traps. So the hypervisor can handle it. In para-virtualized environment the Hypervisor can provide an API for the Guest OS instead of using traps.
- Full virtualization: “trap and emulate”
- Para virtualization: more opportunity for innovation
Control Transfer
Full virtualization
- implicit (traps) guest → hypervisor
- software interrupts (events) hypervisor → guest
Para virtualization
- explicit (hypercalls) guest → hypervisor
- software interrupts (events) hypervisor → guest
Guest has control via hypercalls on when event notifications
need to be delivered.
Data Transfer
Full virtualization
- implicit
Para virtualization (e.g. Xen)
- explicit ⇒ opportunity to innovate
Xen I/O-Rings
Xen uses a ring buffer for data transfer with producer-consumer pattern. There are 4 pointer to the buffer.
- Request producer (shared, updated by guest)
- Request consumer (private to Xen)
- Response producer (shared, updated by guest)
- Response consumer (private to guest)
Memory Models
- Memory Consistency: What is the Model presented to the Programmer?
- Cache Coherence: How is the System implementing the Model in presence of private caches?
Sequential Consistency (Memory Model)
Access to a shared memory location is performed in sequence by the processors. The accesses can be interwoven.
Cache Coherence
Non cache coherent shared address space multi processor (NCC shared memory multi processor)
System only gives access to shared address space. System Software maintains chaching.
- Shared address space available for all processors
- Private caches
If you modify data it’s a problem of the system software to make sure the caches are coherent!
CC shared memory multi processor
- Hardware provides shared address space
- Maintains cache coherence in hardware
Write-Invalidate
Hardware ensures that written memory location is invalidated in all caches.
Write-Update
Hardware ensure that modified memory location is updated in all caches.
“Shared memory machines scale well when you don’t share memory.”, Chuck Thacker
Synchronization
Synchronization Primitives
- Mutex Locks (single exclusive access to resource)
- Shared Lock (Multiple reader to one resource)
- Barriers (Synchronize threads, wait for other threads till all completed their work)
Atomic Instruction
During the execution of an instruction the processor can not be interrupted.
Aquiring a lock needs to be atomic.
Read-Modify-Write (RMW)
Different aproaches:
- Test-and-Set (T+S): Reads a memory location. Then returns the actual value and sets it to 1 atomically.
- Fetch-and-Inc: Reads a memory location. Then returns the actual value and increments it atomically.
- Fetch-and-: Generally with any given function () after fetching and returning the actual value.
Scalability issues with Synchronitation
- Latency: Latency is the time that a thread needs to acquire a lock.
- Waiting time: The time that a thread needs to wait to get the lock. This time is in the hands of the application developers and not of the OS developers.
- Contention: If a lock is released and several threads are waiting for it. How long does it take until a thread is chosen from the waiting threads.
Spinlock
Naive Spinlock (Spin on T+S)
A thread or processor waiting for a lock loops (spins) without doing any useful work.
LOCK(L):
WHILE(T+S(L) == locked);Problems with this naive spinlock implementation:
- Too much contention: Every processor tries to access lock.
- Does not exploit caches: Private caches in processor can’t contain lock variable (T+S needs to be atomic. That’s not possible with cached variables).
- Disrupts useful work: After releasing a lock a processor usually wants to do some work. But other processors need resources for trying to acquire the lock.
Caching Spinlock (Spin on read)
Waiting processors spin on cached copy of L. So there is no communication to memory. The cached copy
of L is updated by the cache coherence mechanism of the system.
LOCK(L):
WHILE(L == locked); // Spinning on cached var. Reading L is atomic.
IF(T+S(L) == locked) // Read L from memory (not cache).
go back; // If it fails start spinning on cached L again.- Less traffic on bus.
- Disruptive.
Spinlock with Delay
If a lock is released every process waits for a given time before trying to aquire the lock.
Delay after lock release
WHILE((L == locked) or
(T+S(L) == locked))
{
WHILE(L == locked);
delay(d[Pi]); // when I get the lock I wait a while
}The delay time is dependent on the processor.
Delay with exponential backoff
WHILE(T+S(L) == locked) // not using chaching at all
{
delay(d); // d is small at first
d = d * 2;
}Every time when the lock is checked and not free the processor waits a longer time before trying again. T+S can be used because we wait before trying to quire the lock again. This reduces the contention. This algorithm works also on architecture without chaches (or cache coherent system in HW).
Ticket Lock
The process that tries to acquire a lock gets a ticket. When the lock is released the process is notified.
This adds fairness to the locking algorithm.
But it causes contention.
Summary
- Spin on T+S, Spin on read and Spinlock with Delay are not fair
- Ticket Lock is fair but noisy (contention)
Queuing Lock
Array-based queuing Lock (Anderson Lock)
For each lock there is an array with flags. The size of the array is equal to the number of processors.
Flags:
- has-lock (hl)
- must-wait (mw)
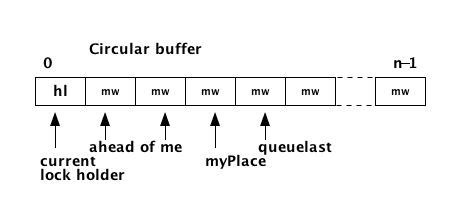
Only one slot can be marked as hl.
The slots are not statically associated with a particular processor.
LOCK(L):
myPlace = fetch_and_inc(queuelast);
WHILE(flags[myPlace mod N] == mw);
UNLOCK(L):
flags[current mod N] = mw; // release lock for feature use
flags[(current+1) mod N] = hl; // next processor in queue gets lock- Only one atomic operation needed per critical section
- Fairness: first-come, first-served
- But needs a lot of space. For each lock there is one array with the size of number of processors
Link Based queuing Lock
The Locks are stored in a linked list.
Synchronization for adding and removing clients to a lock.
Published by John M. Mellor-Crummey and Michael L. Scott (MCS)
Parallel Architectures
OS:
Spring
Wikipedia:Spring (operating system)
An Overview of the Spring System
- Indepentant of programming language (CORBA IDL)
- OOP
- Microkernel
- Spring Nucleus: secure objects with high speed object invocation between address spaces and networked machines
- Object managers:
- e.g. file system: file objects
- running in non-kernel mode
- like server
- IDL (CORBA) Generate:
- Interface (e.g. header file)
- Client side stub code: get access to object implemented in other address space or machine
- Server side stub code: used by object manager to translate remote object invocations into the run-time environment of object implementation
- Serverless objects
- entire state of object always in clients address space
- passing to other address space: copy entire state
- Subcontracts
- plugging different kinds of object runtimes
- control how
- object invocation is implemented
- object references are transmitted between address spaces
- object references are released
- …
- Subcontracts
- Singleton
- Replication
- Cheap objects
- Caching
- Crash recovery
- …
Overall System Structure
- Microkernel
- Processes, IPC and Memory management part of kernel (Liedtke)
- Kernel mode
- Nucleus: processes and IPC
- Entered by trap mechanism
- Virtual Memory Manager
- page faults
- external pagers (looks like any other object server)
- …
- Nucleus: processes and IPC
- All other system services implemented as user-level servers
- naming
- paging
- network IO
- file systems
- keyboard management
- …
- inherently distributed: all services and objects available on one node are also a available on other nodes in the distributed system
Nucleus
- Three basic abstractions: domains, threads and doors
- No memory management
- Domains
- analogous to processes in Unix or tasks in Mach
- address space for applications
- resources: threads, doors, …
- Threads
- execute within domains
- Doors
- Cross domain calls
- OOP calls between domains
- entry points to domains
- represented by a PC and a unique value (nominated by domain)
- unique value used by object server to identify state of object
- unique value might be a C++ pointer
Doors
- pieces of protected nucleus state
- each domain has a table with doors it has access to
- refers to doors using door identifiers
- same door may be referenced by several different door identifiers in different domains
- possesion of door: right to send invocation request to door
- valid door can be obtained with consent of
- target domain
- someone who already has door identifier to that door
- doors can be passed as arguments or be returned as values from functions
Object invocations via Doors
- cross-address-space invocation
- Algorithm
- nucleus allocates server thread in target address space
- nucleus transfers control to that thread, passing information about door and the arguments of the invoked method
- when the called thread returns:
- deactivation of the thread
- activation of caller thread
- passing return data
Network Proxies
rovide object invocation across network
- connect nuclei of different machines transparently
- proxies are normal user-mode domains (no special support from nucleus)
- client and server need not to be aware that proxies exist: normal door invocation
Security model
- secure access to objects
- two basic security mechanisms:
- Access Control Lists
- software capabilities
- invocations are controlled by nucleus doors and front objects
Virtual Memory
- demand-paged virtual memory system
- per machine virtual memory manager (VMM) handles local memory:
- mapping
- sharing
- protection
- transfer
- caching
- depends on external pagers for accessing store and maintaining inter-machine coherency
- Address Space and Memory objects used by clients
- Adress Space:
- virtual address space of domain
- implemented by VMM
- Memory
- abstraction of memory that can be mapped to address space
- can be a file
- operations to set and query length and bind
- no read/write or page-in/out operations
- Separating memory from interface for paging
- useful for implementing filesystem
- Memory Object server can be on different machine than the Pager Object server
Cache and Pager Objects
- two-way connection between the VMMs and external pagers
- cache must be coherent between more than one VMM
- VMM obtains data by invoking pager object implemented by external pager
- external pager performs coherency actions by invoking cache object implemented by a VMM
- the coherency protocol is not specified by the architecture: external pagers can implement any coherency protocol
File System
- file objects implemented by fileserver
- file objects may be memory mapped
- access to files on local disks or over the network
- Spring security and naming architectures to provide access control and directory services
- Spring file system typically consists of several layered file servers
Spring Naming
- Naming for:
- users
- files
- printers
- machines
- services
- …
- uniform name service
- any object can be bound to any name
- Object can be:
- local to a process
- local to a machine
- resident on the network
- transient or persistent
- standard system object
- process environment object
- user specific object
- new name spaces can be compose of different name spaces
- name service allows objects to be associated with a name in a context
- objects need not be bound to a name
- naming graph (name space):
- a directed graph
- nodes with outgoing edges are contexts
- naming provide persistence
- access control and authentication
UNIX Emulation
- Spring can run Solaris binaries
- implemented by user-level code
- contains no UNIX code
- two components:
- a shared library (libue.so), dynamically linked with each Solaris binary
- a set of UNIX-specific services
Barrelfish
- Multikernel
- OS as distributed system of functional units (network of independent cores)
- communication via explicit messages (message passing)
- Design principles
- Make all inter-core communication explicit (message passing)
- Make OS structure HW-neutral
- View state as replicated instead of shared
- Single computer as networked system
- RPC
- latency is lower than shared memory access
- asynchronous or pipelined RPC: client processors can avoid stalling on cache misses
- Asynchronous messaging: event-driven programming
- pitfalls with shared data structures in scalable progams:
- correctness
- performance
- lock granularity
- field layout in structures (alignment …)
- applications can share memory across cores, but OS design does not reky on shared memory
- networking optimizations for message passing:
- pipelining: a number of requests in flight at once
- batching: sending or processing a number of messages together
- Multikernel separates OS structure from hardware
- Replication of state is a useful framework for:
- changes to the running cores
- hotplugging processors
- shutting down subsystems to save power
- Replication:
- Benefit of performance and availability
- at cost of ensuring replica consistency
- porting application to Barrelfish are straightforward
- standard C and mate library
- Virtual Memory Management
- subset of POSIX threads and file I/O APIs
System Structure
- multiple independent OS instances
- communication via explicit messages
- each OS instance per core
- privileged mode CPU driver
- user mode monitor process
- CPU driver local to core
- monitor
- performes inter-core coordination
- coordinate system-wide state
- handling message-oriented inter-core communication
- mostly processor-agnostic
- monitor and CPU driver encapsulate: scheduling, communication and resource allocation
- device drivers and system services (network stack, memory allocators …) run in user mode
- device interrupts are routed in hardware to the appropriate core
- CPU driver
- enfonces protection
- performs authorization
- timeslices processes
- mediates access to core and associated hardware (MMU, APIC …)
- completely event-driven and non-preemptable (single threaded)
- processes events: traps from user processes, interrupts from devices to other cores
- Process structure
- collection of dispatcher objects (cores)
- dispatchers scheduled by local CPU driver
- Inter-core communication
- user-level RPC (URPC):
- marschaling code generated with stub compiler
- name service to locate services
- channels established between services (setup performed by monitors)
- no shared memory other than URPC channel and packet payload
- user-level RPC (URPC):
- cross-core thread management is performed in user-space
- thread schedulers exchange messages to create and unblock threads and migrate threads between cores
- POSIX like threads
Memory Management
- global set of resources
- user-level app and services services use shared memory across multiple cores
- capability system ( seL4)
- virtual memory management (allocation/manipulation of page tables…) entirely in user-space
- capability code is complex
Knowledge and Policy Engine
- Maintaining knowledge of hardware in ‘system knowledge base’
- subset of first-order logic: The ECLiPSe Constraint Programming System
- declarative approach
- hardware discovery