Motivation
- Information Systems Design
- Conceptual Design -> Technical Design -> Implementation
Orthogonal Persistence
Data has to outlive the execution of the program
- Independence of longelivety of data
- How much code needs to be written for persistence (effort for programmer)
- None at all would be nice but not realistic (GUI objects usually don’t need storing…)
- Data is stored automatically
- Not always desirable: don’t need to store UI, messages …
- 3 possible solutions
- implicit: save all objects automatically
- explicit: objects need to be saved manually
- on class base (different granularity)
- How much code needs to be written for persistence (effort for programmer)
- Data Type Orthogonality all data objects should be allowed to be persistent (long-lived, transient)
- The data types do not need to be modified (implicitly or explicitly) to allow persistence
- e.g Serializable interface in Java does not satisfy this criteria (classes that don’t implement the interface can’t be stored)
- Identification: mechanism for identifying persistent object not related to the type system
- Transferring data from persistence storage to memory
- e.g specify which classes/objects should be stored persistence
- separation of concerns
No commercial DB system fully satisfies the above criteria
Impedance Missmatch
- Difference between models
- OOP data model is based on object trees
- The Relational Model is based on tables
- OOP Languages
- Difference between attributes and relationships not clear
- Both are (usually) reference types in a class
- Different models because there are different requirements
- Mapping code between the two models needed
- A lot of solutions available
- Affects run-time (and often development)
- Inheritance (OOP) is difficult to model in relational DBs
- Objects spread over several tables (other approaches possible)
An overview of the mismatch is shown on Tutorialspoint
| Mismatch | |
|---|---|
| Granularity | An object model can have more classes than the number of corresponding tables in the DB. |
| Inheritance | In OOP inheritance is a base concept. The Relational Model doesn’t support this directly. |
| Identity | The Relational Model defines identity. In OOP there is often a difference between equality and identity. |
| Association | OOP uses references. The Relational Model uses foreign keys. |
| Navigation | OOP uses following references in object tree. The Relational Model uses queries. |
Relational Databases
- Tables, Rows, Columns…
- Table: Relation (similar to class)
- Columns: Relation attributes (correspond to class attributes)
- Keys: Pointers (relationships)
It’s difficult to match the relational database model to the object oriented model
Object-relational mapping (ORM)
- Object-relational mapping can be used against object-relational miss-match
- But it’s not a very good approach
- There are a lot of solutions: Hibernate, QxOrm, …
Develop own Database
- Support application development (programming language)
- Clients of the DB system are developers (not end user)
- Support persistent data management
- One data model (OOP)
- One language (Java?)
SQL
Data Definition Language (DDL)
Definition of data models
- Concepts
- Relations
- Relation attributes and domains
- Primary and foreign key
- Operations
- Create tables (
classin Java) - Declare relation attributes
- Declare primary and foreign keys
- Alter tables
- Create tables (
Data Manipulation Language (DML)
Creation and management of data
- Concepts
- Relation touple
- Predicate
- Operations
- Insert
- Update
- Delete
- in Java:
newand ‘setters’
Query Language (QL)
Retrieval of data
- Concepts
- Query
- Predicate
- Query result
- Operations (Relational Algebra)
- Project
- Join
- Select
- in Java: ‘getters’
DDL, DML and QL in SQL and Java
DD, DM supported in Java. Querying is very limited.
- DD
SQL
CREATE TABLE name ...Java
class Person {
String name;
String email;
}- DM
SQL
UPDATE name ...Java
new Person()
p.name = "Bill Stinnet"- Querying
SQL
SELECT col_name ...Java
... = p.nameLINQ is a powerful and compile time safe support for querying.
Learning Goals
- Motivation for Database technologies (not relational)
- Design- and run-time
- Complex application domains
- Schema and data evolution
- Understanding of object-oriented data model
- what is OOP?
- ODMG
- New and alternative concepts and applications
- Develop an object database
- Requirements
- Challenges
- integration with application
- duplicate objects
- OO-specific indexing
- …
- Object database technologies
- Products
- db4o
- Object Store
- Objectivity
- Versant
- General concepts
- Solutions to the challenges
- Products
- Comparison to other database technologies
- Android SDK
- Hibernate
- Django
- …
General Topics for DB’s
[Prepared Statement]
CRUD and ACID
-
The acronym CRUD stands for the basic functions of a database system
- Create
- Read
- Update
- Delete
-
The acronym ACID stands for the properties that allow for concurrent database transactions
- Atomicity
- Consistency
- Isolation
- Durability
ODMG Standard
-
What is an object?
- Something that can be pointed to?
- Can be passed on as a reference?
- Distinct from single values
- properties and behaviour
- representing something (moddeling the real world)
-
Object:
- properties
- behaviour
- presenting something (modelling the real world)
Examples in Java:
| Simple | Complex | |
|---|---|---|
| Reference | Integer | Object |
| Value | int | N/A |
In some languages (PHP, JavaScript, …) Objects and Associative Arrays are the same (or similar).
-
Some constructs can be extended over time
- possible with map (add key/value)
- not possible with class in Java
-
Object Orientation needs a broader definition!
- not coupled to a specific programming language
-
Most database systems often independent of programming languages
- e.g SQL very different from the language where the DB is used (independent of language)
-
Object database systems are more coupled to one (or multiple) programming language
Object Data Management Group (ODMG)
Object Model
-
Based on OMG object model
-
Basic modeling primitives
- object: unique identifier (identity)
- literal: no identifier
-
Object state defined by the values (properties)
- attributes
- relationships
-
Object behavior
- set of operations (can be executed)
-
Objects and literals are categorized by their type
- A type defines common properties and common behavior
Types
- Specification
- properties
- attributes
- relationships
- operations
- exceptions
- properties
- Implementation
- language binding
- a specification can have more than one implementation
- Similar to C++
- Header-File: Specification
- Source-File: Implementation
Type Specifications
- Interface
- defines only abstract behavior
interface Employee {...};
- Class
- defines both abstract behavior and abstract state
class Person {...};
- Literal
- defines abstract state
struct Complex { float real; float imaginary; };
Type Implementation
- Representation
- data structure
- derived from type’s abstract state by the language binding
- for each property contained in the abstract state there is an instance variable of an appropriate type defined
- Methods
- procedure bodies
- derived from type’s abstract behavior by the language binding
- also private methods with no counterpart in specification
Subtyping and Inheritance
-
Two types of inheritance relationships
- IS-A relationship
- inheritance of behavior
- multiple inheritance, name overloading disallowed
interface Professor : Employee {...};
- EXTENDS relationship
- inheritance of state and behavior
- single inheritance
class EmplPers extends Person : Employee {...};
- IS-A relationship
-
Co- and Contravariant rules must hold
- Input Arguments: Contravariant
- Return Values (and Exceptions): Covariant
Object Query Language (OQL)
Based on ODMG Object Model and SQL-92
select list_of_values
from list_of_collections_and_typical_members
where conditionSELECT: Get attributesFROM: The base population of potential results to search inWHERE: Predicates (conditions) that have to be true so that the results are selected as result
Mapping to OOP not obvious.
Table in relational DBs has tow roles:
- Defining Type
- Container of all values (of that type)
In OOP 2. is missing. A class just defines a type but is not a container of all instances of that class.
ODMG defines Extents.
Difference to SQL
This is illegal as the “dot” operator cannot be applied to a collection of objects:
select a.authors.title
from Authors a
where a.name = "Tilmann Zaeschke"Correct solution based on correlated variables:
select p.title
from Authors a, a.authors p
where a.name = "Tilmann Zaeschke"Return Types
- Queries return sets, bags or lists
As a default, queries return a bag
select first: p.authored_by[1], p.title, p.year
from Publications pIn Java:
Bag<Struct { Author first, string title, integer year }>Queries with DISTINCT return a set
select distinct a.name
from Authors aIn Java:
Set<Struct { string name }>Queries with ORDER BY return a list
select p.title
from Publications s order by p.year descIn Java:
List<Struct { string name }>Extents
- Extent of a type is the set (collection) of all active instances
class Person: extent of class Person would be the set of all person objects in the data management system
- Extents can be maintained automatically
Collections
OMDG supports collections:
- set: un-ordered, no duplicates
- bag: un-ordered, duplicates
- list: ordered, elements can be inserted
- array: ordered, elements can be replaced
- dictionary: maps keys to values
| Single elements | Duplicates | |
|---|---|---|
| Ordered | ? (heap) | list |
| Un-ordered | set | bag |
Support for objects and literals:
- Collection objects:
Set<t>,Bag<t>,List<t>,Array<t>,Dictionary<t,v> - Collection literals:
set<t>,bag<t>,list<t>,array<t>,dictionary<t,v>
Sub-collections
OMDG supports sub-collections
Relationships
-
All relationships are binary
- many-to-many
- many-to-one
- one-to-one
-
No support for ternary (or higher) relationships
- can be simulated by creating classes to represent relationship touple
-
System maintains referential integrity!
-
Keywords for attributes and relationships
attribute: for normal class attributesrelationship: for relationship references (integrity checks can be performed)
Persistence
- Persistence by reachability
- not necessary the best option
- Database gives access to global names
- explicitly named root objects
- types defined in schema
- named extents of types
- store object graphs
Other Concepts Supported
- Database operations
- Locking and concurrency control
- Transactions
- Access to meta-data
- Built-in structured literals and objects
- dates
- times
- time-stamps
- intervals
- …
Object Definition Language (ODL)
- programming language independent, extensible and practical
- compatible to OMG Interface Definition Language (IDL)
ODL Syntax:
class name [ ( extent name, key name ) ] {
{ exception name { { type name } } }
{ attribute type name }
{ relationship type name inverse relationship }
{ type name({ (in|out|inout) type name })[raises ({ exception })] }
}- extent and key of a class can be specified optionally
- relationships specify inverse to maintain referential integrity
- method signatures are implemented by language binding
Collection Expressions
- Aggregate operators
AVG,SUM,MIN,MAX, andCOUNTapply to collections that have a compatible member type
- Operations for sets and bags
UNION,INTERSECTIONandEXCEPT- inclusion tests (subset, super-set)
- Special operations for lists
- Simple coercion
- a collection of one element can be coerced to that element using the
ELEMENToperator
- Flattening a collection of collections
Language Bindings
- C++
- Java
- Smalltalk
- …
Hibernate
- Example of a Object-relational mapping tool
- Challenges
- Data has to outlive the execution of the program
- The program is written in an OOP language

- Problems of Object Identity
- Two object graphs can point to same objects
- Duplicates can be created When deserialized
- Programmer must take care to avoid multiplicity!
- Object Identity
- Multiple models
- Impedance mismatch
- Transformation must be implemented (Design Time)
- Transformation must be carried out (Run Time)
- Must be implemented for each application
- Possible use of SQL
- Integrating a relational database at the level of SQL (e.g. JDBC, Google Android, PHP mysqli)
- OK for simple application domains (e.g. few classes with base type attributes)
- Not OK for complex application domains (e.g. many classes with reference type attributes, multi-valued attributes, associations, inheritance)
- Integrating a relational database at the level of SQL (e.g. JDBC, Google Android, PHP mysqli)
Object-Relational Mappings
- Map object-oriented domain model to relational database
- Hibernate
- Free implementation for Java
- maps Java types to SQL types
- transparent persistence for classes meeting certain requirements
- generates SQL for more than 25 dialects behind the scenes
- provides data query and retrieval using either HQL or SQL
- can be used stand-alone with Java SE or in Java EE applications
- Java Persistence API (JPA)
- Defines interface (and annotations) to use y other systems
- Enterprise Java Beans Standard 3.0
- introduced annotations to define mapping
- javax.persistence package
- Hibernate
Main Concepts
Configuration- Connection to database (hibernate.properties or hibernate.cfg.xml)
- Which DBMS? (MySQL, HSQL, …)
- Which DB Instance? (Database Name)
- Mappings between classes and database tables
- The Configuration object is created at first
- usually created only once during application initialization
SessionFactory- Created by using the configuration object
- Session objects can be created and supplied with configuration
- Heavyweight object: create during start up and keep for later use
- multiple databases require multiple
SessionFactoryobjects
Sessionobject- Used to get physical connection to the database
- lightweight
- designed to be instantiated each time an interaction with the DB is needed
- Persistent objects are stored and retrieved through
Sessionobject - should not be kept open for a long time
- usually not thread safe
- create before use
- destroy after use
Transactionobject- represent a unit of work with the DB
- handled by underlying transaction manager and transaction (JDBC or JTA)
- optional object
- transactions can be managed in own application code
Queryobject- SQL or Hibernate Query Language (HQL)
- bind query parameters
- limit number of results
- execute query
Criteriaobject- used to create and execute object oriented criteria queries to retrieve objects
Configuration
- Hibernate needs to know where to find some information about class mappings and database
- XML file: hibernate.cfg.xml (or Java properties file hibernate.properties)
Properties
| Property | Description |
|---|---|
| hibernate.dialect | The SQL dialect used to generate persistence code |
| hibernate.connection.driver_class | The JDBC driver class |
| hibernate.connection.url | The URL to the database instance |
| hibernate.connection.username | The username for the database |
| hibernate.connection.password | The password for the database |
| hibernate.connection.pool_size | The number of connections in the Hibernate database connection pool |
| hibernate.connection.autocommit | Autocommit mode for the JDBC connection |
There are additional settings for using a database along with an application server and JNDI.
Persistent Objects
Only Plain Old Java Object (POJO) can be saved in the DB.
Requirements:
- Default constructor
- Class should contain an ID
- Maps to the primary key column in DB table
- Attributes should be private
- Public accessor functions (getter, setter) need to be provided
- JavaBean style accessors: getXYZ, setXYZ
- Persistence class either
- non-final or
- implementation of interface that declares all public methods
- Some additional minor restrictions from EJB framework
Example:
SessionFactory factory = new Configuration().configure().buildSessionFactory();- Session
- Connection to a database instance
- Created when we want to work with a database
- Using a Session object, we can store and retrieve application data
- Methods:
- save
- createQuery
- update
- delete
Example:
Session session = factory.openSession();
...
session.save(person);
...
session.close();- Transaction
- Opened with a Session object
beginTransaction()and closed usingcommit()
- Opened with a Session object
Example:
Transaction tx = session.beginTransaction();
...
tx.commit();- Query
- Represents a query (e.g.
SELECT * FROM PERSONS, HQL). - Result is a list
- Represents a query (e.g.
Example:
List persons = session.createQuery("FROM Persons").list();
for (Object p: persons)
{ ... }- Criteria
- An object-oriented representation of query criteria
Mapping Associations
- Uni- and bidirectional associations
- Unordered and ordered associations
- Association cardanality types
- one-to-one
- many-to-one
- one-to-many
- many-to-many
- Join Tables to map complex associations
Example:
CREATE TABLE AUTHOR(AUTHOR_ID BIGINT NOT NULL PRIMARY KEY, ...)
CREATE TABLE AUTHORSPUBLICATIONS(
AUTHOR_ID BIGINT NOT NULL,
PUBLICATION_ID BIGINT NOT NULL,
PRIMARY KEY(AUTHOR_ID, PUBLICATION_ID))
CREATE TABLE PUBLICATION(PUBLICATION_ID BIGINT NOT NULL PRIMARY KEY, ... )Mapping Inheritance
- Multiple strategies
- One table per class hierarchy
- One table per subclass
- One table per concrete class
- Mapping strategies can be mixed
- Different parts of inheritance hierarchy can have different strategy
- Implicit polymorphism
- One table per concrete class
- Common interface not mentioned in the mapping
- Common properties are mapped in every table
Annotations
- Since Java 5
- Java Persistence API (JPA, Enterprise Java Beans 3.0)
- Annotations instead of XML for mapping
- Standardizes ORM
- Hibernate implements JPA
Google Android
- Linux based OS
- Default applications: Search, Maps, Mail, Calendar, Contacts…
- Java SDK
- Support for persistent data management
- Smart Phone / Tablet
Application component model
-
Activity (UI)
-
Service (API, Computation)
-
Broadcast Receiver (Events)
-
Content Provider (Data Management)
-
Manifest
- lists the application components
- sets activity to be shown at startup
- components can be made available to other applications
-
Intent: request the use of application components (integration with other apps)
- showing activities
- using content provides
- listening to events
- starting services
- …
-
- States: New Activity, Running, Paused, Stopped, Destroyed
- Extend
Activity - Application can react to state changes
Data Management
-
Low-level: SQL
-
High-level: Content Provider
-
Database Instance
- SQLite
- CRUD
- Create (Insert)
- Read (Retrieve, Query)
- Update
- Delete
-
Cursor
- Iterator over result
- Methods
isLast()andmoveToNext() - Type specific getter methods (e.g
getInt(3)) - Access with index
- Index can be retrieved
getColumnIndex(String colName)
-
Content Provider
- Abstract class implemented by application
- Uses
- Cursor
- URI
- ContentValue
Object-Oriented Databases: Object Database Manifesto
-
Avoid impedance mismatch
-
Provide uniform data model
-
Combine features of
- OOP
- Database Management Systems
-
The object-oriented database manifesto
- 13 mandatory features
- 5 optional characteristics
- 4 open choices
- several important topics not addressed
-
Object-oriented systems (mandatory)
- 1. Complex objects
- 2. Object identity
- 3. Encapsulation
- 4. Types and classes
- 5. Type and class hierarchies
- 6. Overriding, overloading and late binding
- 7. Computational completeness
- 8. Extensibility
-
Database management systems (mandatory)
- 9. Persistence
- 10. Efficiency
- 11. Concurrency
- 12. Reliability
- 13. Declarative query language
Objects (mandatory)
-
Complex objects
- build from simpler objects (constructor)
- collections
-
Object identity and equality
- Object ID (OID)
- unique and immutable
- sharing of objects (references)
- identical objects have same OID
- equal objects have same state
- shallow and deep equality
- Object ID (OID)
-
Touple: entities and their attributes
-
Sets: collections of entities
-
Lists: order
-
Constructor orthogonality
- supports arbitrary nesting such as
- sets of sets
- set of records
- records containing records
- …
- In contrast, relational databases only support
- sets of records (relation with touple) and
- touple containing atomic values
- supports arbitrary nesting such as
-
Complex objects also require
- transitive retrieval and deletion of objects
- deep and shallow copying
- …
-
Encapsulation
- interface
- signatures of public methods
- implementation
- includes data and methods
- object state modification only through public methods
- object data structure may be exposed for declarative queries!
- interface
Types and Classes
- Data types
- definition of object properties
- static part: object structure
- dynamic part: object behavior
- separation of interface and implementation
- Check of correctness at compile time
- Object classes
- container for objects of the same type
- objects can be added and removed
- used to add, remove and iterate over all existing objects
- to present, manipulate … them
Generalization Hierarchies
- Powerful modeling tool
- Reuse (specification and implementation)
- Inheritance
- Substitution principle
- Inherited attributes and methods (from super-class)
- New attributes and methods can be added (in subclass)
- Migration between classes
- move objects between hierarchy levels
- object specialization and generalization
Durability and Efficiency
-
Persistence
- data has to survive the program execution
- orthogonal persistence
- implicit persistence
-
Secondary storage management
- index management
- data clustering
- data buffering
- access path selection
- query optimization
-
Orthogonality
- Persistence applicable to all objects of any type
- No additional code necessary
- Moving objects between persistent and memory representation is not needed
-
Similar requirements for secondary storage management
- As a rule of thumb:
- a database should work without it, but with it, it should perform better
- If this requirement is met, a complete separation of the logical and physical level is achieved
- As a rule of thumb:
Concurrency Control and Recovery
- Concurrency
- management of multiple users concurrently interacting
- atomicity, consistency, isolation and durability
- serialisability of operations
- Reliability
- resiliency to user, software and hardware failures
- transactions can be committed or aborted
- restore previous coherent state of data
- redoing and undoing of transactions
- logging of operations
Declarative Query Language
- High-level language
- express non-trivial queries concisely
- text-based or graphical interface
- declarative
- Efficient execution
- possibility for query optimization
- Application independent
- work on any possible database
- no need for additional methods on user-defined types
db4o
- Open Source project
- Java and .NET
- Features
- No conversion of mapping needed
- Classes don’t need to be changed to make them persistent (datatype orthogonality)
- One line of code to store (complex) objects
- local or client/server mode
- ACID transaction model
- Automatic management and versioning of database schema
- Small memory foot-print (single 2Mb library)
Object Container
- Represents db4o databases
- local file mode or
- client connections to db4o server
- Owns one transaction
- operations are executed transactions
- transaction is started when object container is opened
- after commit/rollback next transaction is started automatically
- Manages link between stored and instantiated objects
- object identities
- loading, updating, unloading
Storing Objects
- Store objects with method
ObjectContainer.store(...) - Arbitrary complex objects can be stored
- Persistence by reachability
Retrieving Objects
- 3 Query languages
- Query by Example
- simple
- based on prototype objects
- selects exact matches only
- Native Queries
- expressed in application programming language
- type safe
- transformed to SODA (optimized)
- Simple Object Data Access (SODA)
- query API based on query graph
- methods for descending graph and applying constraints
- Query by Example
SODA Queries
- Expressed using
Queryobjectsdescendadds or traverses a node in the query treeconstrainadds a constraint to a node in the query treesortBysorts the result setorderAscendingandorderDescendingexecuteexecutes the query
- Interface Constraint
greaterandsmallercomparison modesidentity,equalandlikeevaluation modesand,orandnotoperatorsstartsWithandendsWithstring comparisonscontainsto test collection membership
Updating Objects
- Update procedure for persistent object
- retrieve desired object from the database
- perform the required changes/modifications
- store object back to the database (calling
storemethod)
- db4o uses IDs to connect in-memory objects with stored objects
- IDs are cached
Deleting Objects
- similar to updating objects
- Method
ObjectContainer.delete(...)removes objects
Simple vs. Complex Objects
- Simple Structured Objects (objects in classical sense):
- properties
- methods
- Complex Object Structures: multivalued attrivutes
- arrays
- collections
- …
Simple Structured Objects
- New objects are stored using the
storemethod- Persistence by reachability
- Object graph is traversed, each referenced object is stored
- Persistence by reachability
- Updating objects with
storemethod- Update depth 1 by default
- Only primitives and strings are updated
- No traversal of object graph (performance)
- Deleting objects with
deletemethod- Not cascaded by default
- Referenced objects have to be deleted manually
- Cascading delete can be configured for individual classes
Updating Simple Structured Objects
- Cascading updates are configured per class with
ObjectClass.cascadeOnUpdate(..) - Update depth can be configured
ExtObjectContainer.store(object, depth)updates referenced objects to given depthObjectClass.updateDepth(depth)defines update depth for a class (and all its objects)Configuration.updateDepth(depth)sets global update depth for all objects
Deleting Simple Structured Objects
- Cascading deletes similar to cascading updates
- configured per object class
CommonConfiguration.objectClass (...)ObjectClass.cascadeOnDelete(..)- What happens if deleted objects referenced elsewhere???
- Cache and disk can become inconsistent when deleting objects
ExtObjectContainer.refresh(..)syncs objects
Object Hierarchies
- Complex object structures are handled automatically
- hierarchies, composite hierarchies
- inverse associations
- inheritance and interfaces
- multi-valued attributes, arrays and collections
- db4o database-aware collections
ArrayList4andArrayMap4implement Collections API- as part of transparent persistence/activation framework
ActivatableArrayList,ActivatableHashMap, …
- complex object implementation becomes db4o dependent
Transparent Persistence
- Persistence should be transparent to application logic
- Store objects in database once (
storemethod) - avoid multiple calls of
store
- Store objects in database once (
- Logic of transparent persistence framework
Activatableinterface (no datatype orthogonality)- objects are made persistent by
storemethod - objects bound to transparent persistence framework with
bindmethod - commit: transparent persistent framework scans for modified objects and invokes
store
Enabling transparent persistence
config.add(new TransparentPersistenceSupport());Activation
- Activation controls depth of loaded fields
- field values (objects) are loaded in memory to a certain depth when query retrieves objects
- activation depth: length of reference chain
- fields beyond activation depth: default value (e.g
null)
- Activation cases
ObjectSet.next(...)called on an query result- explicit
ObjectContainer.activate(...) - db4o collection element accessed
- members of Java collections are activated automatically when collection is activated
- Controlling activation
- default depth: 5
ObjectContainer.activate(..)andObjectContainer.deactivate()
- per class configuration
Methods for per class configuration of activation depth
ObjectClass#minimumActivationDepth(minDepth)
ObjectClass#maximumActivationDepth(maxDepth)
ObjectClass#cascadeOnActivate(bool)
ObjectClass#objectField(...).cascadeOnActivate(bool)Transparent Activation
- Make activation transparent to application logic
- activate fields automatically when accessed
- Logic of transparent activation framework
Activableinterface (no datatype orthogonality)- at object instantiation db registers itself in object with
bind(..)
Enabling the transparent activation framework
config.add(new TransparentActivationSupport());db4o Transactions
- ACID
- Data transaction journaling
- no data loss in case of system failure
- automatic data recovery after system failure
- thread-safe for simultaneous interactions
- all work in
ObjectContaineris transactional- transaction started when container opened
- current transaction committed when container closed
- explicit commit and rollback possible
ObjectContainer.commit(...)ObjectContainer.rollback(...)
Configuration
- Embedded
Db4oEmbedded.newConfiguration()
- Client/Server
Db4oClientServer.newClientConfiguration()Db4oClientServer.newServerConfiguration()
External tools
- performance tuning
- database diagnostics
- Indexes
- optimize query evaluation
- Defragment
- removes unused fields, classes, management information
- compacts db file, faster access
- command line interface or from application
- Statistics
- queries
- objects: stored, retrieved, activated, …
- I/O, Network, …
- Logger
- logs objects in db
- logs objects of a given class
- run from command line
Indexes
- Trade-off between
- increased query performance
- decreased storage, update and delete performance
- Set by configuration or annotation (
@Indexed) - B-Tree based indexes on single object fields
Tuning for Speed
- Heuristic to improve performance
- weak references
- BTree node size
- free-space manager
- locking
- flushing
- callbacks
- caches
- …
- Object loading
- use appropriate activation depth
- use multiple object or session containers
- disable weak references if not required
- Database tests
- disable detection of schema changes
- disable instantiation tests of persistence classes at start-up
- Query evaluation
- set field indexes on most used objects to improve searches
- optimize native queries
Distribution and Replication
- Embedded mode
- DB accessed by clients in same JVM
- direct file access: 1 user and 1 thread at a time
- client session: 1 user and multiple threads
- Database file opened, locked and accessed directly
Db4oEmbedded.openFile(configuration, name)
- Client/Server mode
- Clients in multiple JVMs
- DB access on server
- Client opens TCP/IP connection to server
Db4oClientServer.openServer(filename, port)Db4oClientServer.openClient(host, port, user, pass)
- Client sends query, insert, update and delete instructions to server
- Client receives data from the server
- Replication
- redundant copies of database on multiple servers
- changes replicated form master to client servers
- several forms of replication supported
- snapshot replication
- transactional replication
- merge replication
- needs to be coded into application
- cannot be configured on admin level
- replication only on demand
- client/server semantics introduced by developer
- one interface for all forms of replication
- Replication Modes
- Snapshot Replication
- Snapshots of master replicated to client
- state-based
- periodical schedule
- special SODA query to detect all new and updated objects
- Transactional Replication
- Changes synchronized after transaction
- operation based
- changes replicated immediately
- Single object replication with
ReplicationSession
- Merge Replication
- Changes from clients merged to central server
- Other clients updated to reflect changes
- Transactionally of on a periodic basis
- Typically if subscribers are occasionally offline
- Snapshot Replication
- Replication System
- Separated from db4o core
- uni- or bidirectional replication
- Replication of relational databases based on Hibernate
- Supported replication providers
- db4o → db4o
- db4o → Hibernate
- Hibernate → db4o
- Hibernate → Hibernate
- 3 steps required
- Generating unique IDs and version numbers
- Creating a
ReplicationSession - Replicating objects
- Mode dependent on implementation
- Bidirectional by default
- Unidirectional can be configured
ReplicationSession.setDirection(from, to)
ReplicationSession.replicate(object)newer object transferred to DB- Object granularity
- Unidirectional can be configured
- Conflict handling has to be done by developer
Callbacks
- Called in response to events
- activate
- deactivate
- new
- update
- delete
- Methods called before and after event
can...called before eventon...called after event
- Interface
ObjectCallbacks - Use Cases
- Recording or preventing updates
canUpdate()andonUpdate()
- Setting default values after refactoring
canNew()
- Checking object integrity before storing objects
canNew()andcanUpdate()
- Restoring state when objects activated
- Update UI, restore network connections, …
- Recording or preventing updates
Object Instantiation
- Three different techniques for instantiation
- Constructor
- Bypassing Constructor
- Translator
- Bypassing Constructor is default (if available)
- Can be configured globally or per class
- Constructors
- db4o tries first default constructor
- if not public default constructor available
- all constructors are tested to create instance
- default values (e. g
null) passed as arguments - first successfully tested constructor is used
- if no instance of a class can be created, object can’t be stored
Configuration interface:
// global setting (default: depends on environment)
CommonConfiguration#callConstructors(true)
// per class setting (default: depends on environment)
CommonConfiguration#objectClass(...).callConstructors(true)
// exceptions for debugging (default: true)
CommonConfiguration#exceptionsOnNotStorable(true)- Bypassing Constructors
- Constructors that cannot handle default values or
nullmust be bypassed - platform specific mechanism
- Not all environments support this feature
- Default setting (if supported by environment)
- Breaks classes that rely on constructors being executed
- Constructors that cannot handle default values or
- Translators
- needed if neither Constructors nor Bypassing Constructors can be used
- if constructor needed to populate transient members
- if constructor fails when called with default values
- Interfaces
ObjectTranslatorandObjectConstructor
- Type Handles
- instead of Translators at lower level
- type handler registered for class that it handles
- write to and read from byte-arrays
Versant
- Highly scalable
- Distributed
- Many platforms and programming languages
- C, C++, Java
- db4o acquired by Versant
- Lot of features
- easy to use
- Full Persistence Orthogonality
- but code is injected (into byte-code)
Indexing
- Like SQL
- Point/Range queries
- Index structures for Relational DBs not ideal for Subtyping
- Polymorphic indexes in Versant
Architecture
- Always network based
- no embedded option (as db4o)
- Client
- Versant Manager
- Object cache
- Application logic
- Versant Server
- possible to use multiple servers
- Access to data
- Volumes (page cache)
- Logical log file
- Physical log file
- Dual cache
- Object cache (client)
- Page cache (server)
Database Volumes
- System Volume (created automatically)
- Class descriptions
- Object instances
- Data Volumes (optional)
- Increase database capacity
- Partition data
- Logical Log Volume (created automatically)
- Transactions and redo information
- For recovery and rollback
- Physical Log Volume (created automatically)
- Physical data information
- For recovery and rollback
Versant Manager
- Presents objects to app
- Caches objects in virtual memory
- Manages transactions
- Distributes queries and updates to servers
- Conversion between Versant DB format and client machine format
Cache
- Cached Object Descriptor Table
- Map from logical object identifier (LOID) to object in memory
- attributes pointing to other object: access object in memory or DB
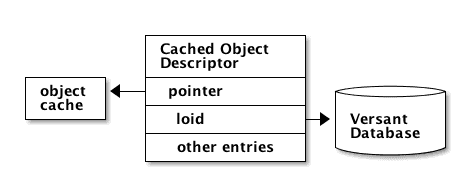
| pointer | LOID | Meaning |
|---|---|---|
| NULL | NULL | object deleted? |
| not NULL | NULL | not saved persistently |
| NULL | not NULL | not loaded in cache |
| not NULL | not NULL | in DB and in cache |
Other entries:
- locking information
- state information
- …
Versant Server
- Object retrieval (disk and page cache)
- Transactions and locks
- Logging and recovery
- Indexing
Versant doesn’t have the notion of activation. Data is retrieved automatically when dereferencing pointers.
Processes, Sessions and Transactions
- Session (same as ObjectContainer in db4o)
- On client side
- Represents database instance
- Container
- A session object is always bound to one single transaction
- It’s possible to have multiple threads attached to one session
- This is dangerous!
- Not transaction support
- Multiple sessions within separate threads
- or multiple session in one thread
- Each session object on the client is bound to one transaction thread in the server
- Transaction (ACID) support
- The server thread accesses the page cache
Java Versant Interface
- Easy-to-use storage of persistent Java objects
- pure Java (syntax and semantics)
- instances of nearly all classes can be stored (and accessed)
- works with Java GC
- Client-server architecture
- access to the Versant object DB
- client libs cache objects for faster access
- DB queries are executed on server
- Configuration and code-generation integrated in build process
JVI Layers
Versant provides different API layers. The fundamental layer is usually not directly needed by the application developer.
Fundamental Layer
-
DB centric
-
Create ‘Meta-classes’
-
Objects manipulated indirectly through handles
-
package
com.versant.fund -
Query classes
FundQueryandFundQueryResult -
Create wrapper code for real classes (reflection)
Transparent Layer
- language centric
- usually used by developer
- code is injected to application code
- build on top of fundamental layer
- package
com.versant.trans - Java classes are mapped to objects in fundamental layer
- Persistent objects are cached in memory
- For persistent objects retrieved from a DB Java objects are constructed (in memory)
First and Second Class Objects
Versant distinguishes first class and second class objects
- Configured externally in a file
- Configured on class basis
- First Class Objects (FCO)
- main objects that can be saved and retrieved independently
- have a Logical Object Identifier (LOID)
- changes are saved automatically (independence)
- strong entities
- Second Class Objects (SCO)
- can be saved only as part of an FCO
- can’t be results of queries
- can be part of first class objects
- stored as binary array
- weak entity
- used for optimization
Persistence Categories
-
can be configured on class basis
-
First class objects
- Persistent always (p)
- becomes persistent at instantiation (independence)
- marked as dirty when modified
- Persistence capable (c)
- new instances are transient but can become persistent
- marked as dirty when modified
- Super-class of p or c must also be p or c respectively
- Persistent always (p)
-
Second class objects
- Transparent dirty owner (d)
- changes to object automatically mark the owner object as dirty
- works only when the owner is stored (FCO)
- Persistence aware (a)
- for code that is aware of FCO
- code needs to mark manually the FCO as dirty
- Not persistent (n)
- no managed by Versant system
- Transparent dirty owner (d)
Persistence and Navigation
- Persistence by reachability is provided
- Database root
- persist the root of an object graph
- name it (for retrieving it later)
- Methods
makeRoot(),deleteRoot()andfindRoot()
- Transparent navigation
- ‘activation’ handled automatically and lazy
- objects are transparently locked and retrieved
- works across DB boundaries
OMDG Layer
- language centric
- ODMG database, transactions, collections
- build on transparent layer
- packages
com.versant.odmgandcom.versant.odmg
Application Development
- Develop Java classes
- make code ‘persistence aware’
- sessions, transactions, concurrency
- Create configuration file
- specify persistence category for each Java class
- Compile
- Run enhancer to make byte-code changes
- persistence behavior inherited from
com.versant.trans.Persistent - explicit at compile time or
- implicit at run time (class loader)
- persistence behavior inherited from
- create DB
- Run application
Byte-code Enhancement
- Code which creates schema object in DB
- Code for writing and reading to and from DB
- Code for accessing attribute values
Object Lifecycle
- Creation of persistent objects
- Java objects in memory
- Each object has internal DB information in object cache
- Commit
- Object data written to DB
- Proxy Java objects retained in memory
- Rollback
- New database objects will be dropped
- Querying
- Queries are passed to DB server
- Proxy object for every object in result
- Accessing objects
- Objects are fetched or de-serialized transparently
Versant Collections
- Standard collection classes can’t be byte-code enhanced
- Special collection classes for FCOs and SCOs
- Scalable large collections (FCO)
- OMDG collections (are FCOs)
- additional query facilities
Versant Query Language (VQL)
- Subset of OQL (ODMG)
- Similar to SQL
- Executed on server
- Can be parameterised
- prepared statements
Event Notification and Persistent Object Hooks
- Like callbacks in db4o
- Event Notification
- Propagation of events from DB to client
- Event types
- class: create, modify or delete an instance
- object: modify or delete object or group of objects
- transactions: begin or end of transaction
- user-defined events
- package
com.versant.event
- Persistent Object Hooks
- Allow intervention of state transitions
activate(),deactivate()preRead(boolean act)andpostRead(boolean act)preWrite(boolean deAct)andpostWrite(boolean deAct)vDelete(): can be used to maintain referential integrity (cascading delete)
ObjectStore
General Topics of Persistence
- Orthogonal persistence is not always desired (UI, messages, …)
- Persistence identification: do we need to explicit store/retrieve objects
- Possibility to select what is in DB and what is in memory
- Declarative query language
- what, not how
- more power-full
- easy to use
- more expressive
- Difference between
- persistent always: stored automatically
- persistent capable: needs to be stored explicitly
Architecture
- C++ and Java
- Client/Server application
- Lightweight and professional editions available
- Based on virtual memory mapping
- pages
- cache forward architecture (very performant)
- Virtual memory mapping architecture (extends operating system)
- logical vs. physical address
- page fault
- address translation
- Characteristics (ObjectStore)
- virtual
- shared
- distributed
- heterogeneous
- persistent
- transactional
- Logical vs. physical address
- data is referenced uniquely using a 4-part key
- database
- segment
- cluster
- offset (in cluster)
- theoretical address space to
- Reserved virtual memory region for persistence: Persistent Storage Region (PSR)
- data is referenced uniquely using a 4-part key
- Physical memory and secondary storage
- all data accessed by client must be in PSR
- cache hold recently accessed data even across transactions
- Data is cached on different levels
- Granularity: pages
- close to persistence capable (in Versant)
- overloaded
newoperator - instance based persistence
- overloaded
Virtual Memory Mapping Architecture
- Page faults
- ObjectStore maps data into app when page fault occurs
- data is paged into memory from cache if not in PSR or fetched from server if not in cache
- Address translation
- done when data is fetched into cache
- re-translation can occur (when PSR gets full)
- trade-off
- nice to have the ability to use direct SW pointers
- translating pointers has scalability implications
Server Side Components
- Server
- Enforces ACID using ‘page permits’
- co-operation between servers with two-phase commits
- automatic recovery mechanism
- Database
- managed by one server
- one server can manage multiple DBs (distribution)
- binary files storing pages of memory containing C++ objects
- managed by one server
- Transaction log
- each server owns transaction log
- pages only propagated to DB when transaction commits
- used for
- automatic recovery
- faster commits
- Multi-version Concurrency Control (MVCC)
- …
Client Side Components
- Client
- C++ program linked with ObjectStore libraries
- even Java programs using ObjectStore are embedded (session) in a C++ part
- interacts with DB
- pages automatically fetched from DB
- Cache
- one cache memory mapped file per client process
- pages fetched from DB are held in cache
- pages can be retained in cache between transactions
- Cache manager retrieves data from the server
- meta-information (Commseg)
- Commseg memory mapped file
- contains meta-information about pages in cache
- stores permit and lock for pages in cache
- permits can be retained between transactions
- Cache manager
- one manager per client machine
- shared by all clients on that machine
- handles permit revokes
- read/write cache and Commseg
- not directly involved in page fetch
- Persistent Storage Region (PSR)
- reserved area of virtual address space (in C++ part)
- addresses of persistent objects used by client are mapped to PSR
- pointers of application will be in the range of the PSR
- at end of transaction PSR is cleared
- can be reused for next transaction
Fetching and Mapping Pages
- Client automatically fetches and maps pages
- ‘lazy’ fetches
- held in client cache
- Server permits and client locks acquired automatically
- ensuring transaction consistency
- Existing page can be swapped out
- if not enough room in cache for new page
- updated pages are sent to the server
- read-only pages are dropped from cache (copy in DB)
Fetching and Mapping Sequence
- ObjectStore installs
SIGSEGV(segmentation fault) handler - Program obtains pointer
pto object on page x - Dereferencing
pcausesSIGSEGVhandler to be called - Virtual mapping table is consulted
- Page is fetched from server and stored in cache
- Page x is mapped to address space
- Execution continues
Cache-Forward Architecture
- To provide high performance in ObjectStore
- data cached across transaction boundaries
- number of used locks is reduces
- cached data kept in globally consistent state
- Two types of locks on pages
- transaction locks: represents state of page during transaction
- ownership permits: represents state of page in cache
- Permits are tracked by server
- server serves permits on pages that are sent to client
- Locks are taken by client
- client can lock pages according to given permit
Shared Virtual Memory
- Lazy call-back mechanism for permits
- Server maintains table of permits for each client
- When client requests page from server
- Server checks for other clients with permit for page (and permit type)
- Server issues call-back if one or more clients have conflicting permits
Page Permits and Locks
- Lock for client (locally)
- Permission for server (globally)
- Read permit
- client can lock page for reading without consulting server
- many clients can hold a read permit for the same page
- Write permit
- client can lock page for reading or writing without asking server
- only one client can hold a write permit for a page at any given time
- Cache manager inspects permit and lock status for call-back
- ✓: Positive
- ✗: Negative, but permit is flagged to be revoked at transaction end
| Permit | Lock | Response |
|---|---|---|
| read | read | ✗ server only calls back permit of other client needs to write |
| read | no lock | ✓ |
| write | read | ✓ permit for page downgraded to read |
| write | write | ✗ |
| write | no lock | ✓ |
- Pages on server are fetched with permission (read or write)
- Local locks don’t tell server about lock/un-lock about after transaction
Distribution and Heterogeneity
- Clients can access objects in different remote DBs in one transaction
- Clients and servers can run on different platforms
- Win
- Linux
- Unix
- …
- Physical object layout is transformed automatically
- by client
- at run-time
- when page is mapped into cache
Persistence
- persistence by instantiation in C++
- Overloaded persistent
newoperator - Several options for object allocation
- transiently on the heap
- DB
- segment
- cluster
- …
- Persistence is orthogonal to the type of an object (data-type orthogonality)
Transactions
- Basic ACID properties
- Atomicity
- after commit: guaranteed that data was written and is recoverable
- after abort: changes are undone
- Consistency
- it’s impossible to apply or lose update while data is written
- Isolation
- serialisability (CPSR) is guaranteed by 2-phase locking
- MVCC provides serialisability for read-only transactions (using snapshots)
- Durability
- changes are written to transaction log first
- background process propagates changes to DB
Transaction Types
- Read or Write
- Local or Global
- local: only initiating thread is allowed
- global: allows all threads in a session to share transaction
- Lexical or Dynamic transactions
- Lexical transactions
- automatically retry on lock
- must start and end in same code block
- always thread-local
- Dynamic transactions
- lower level of
os_transactionclass - better suited for multi-threaded applications
- lower level of
- Lexical transactions
Database Layout
- Memory pages held in hierarchy of clusters in segments
- Segments
- logical partitioning of objects
- Segment 0: schema segment
- DB schema
- DB roots
- Segment 2: default segment
- Segment 4: first user-created segment
- max segments per DB
- Clusters
- group closely related objects
- each segment has default cluster 0
- max clusters per segment
Developing Applications (API)
-
ObjectStore libraries
objectstore: run-timeos_database: DB managementos_transactions: transaction handles and functionalityos_typespec: determine type specificationos_database_root: manage rootsos_segment: segment access and managementos_cluster: cluster access and management
-
Development process
- writing persistent classes, schema file, app logic
- compile schema file with
pssqcompiler - compile classes with C++ compiler
- linking
Managing Databases
- provided by
os_databasecreate(): creates new DBopen(): opens DBsave(): saves DB, changes permanentclose(): closes DB, but doesn’t save statdestroy(): deletes DB
Transactions
- provided by
os_transaction- all interactions with DB must be in a transactions
- can be nested
- defining and working with transactions
- directly using
os_transactionclass (dynamic) - using macros (lexical)
- directly using
Creating Persistent Objects
Use overloaded new operator:
os_database *db = os_database::open("publications.db", 0, 1);
Author *scheel = new(db, os_ts<Author>::get()) Author("Matthias Geel");
db->close();It’s also possible to instantiate persistent array of objects.
Updating and Deleting Persistent Objects
- Changes to persistent objects are propagated to DB automatically
- when pages are sent back to server
- client app updates memory-mapped persistent objects (using standard C++)
- persistent objects are deleted when memory-mapped objects are deleted (using standard C++)
- Fully transparent to app developer
Collections and Relationships
- Relationships between classes modeled as collections
- library of non-templated and templated collection types available
- traversal, manipulation, retrieval
- classes
os_collection,os_Collection<E>and sub-classes
Relationships:
// Relationship to the customers orders:
os_relationship_m_1(Customer,orders,Order,customer,os_List<Order*>) orders;-
Cursors over Collections
- used to navigate and manipulate collections
- class
os_Cursor - cursors can be reused by rebinding to other collection
-
Queries over Collections
- specify
- element type
- query string
- schema DB
- query string indicates selection criterion
- in C++
- or pattern matching expression
- function calls in query strings restricted to basic types
- nested queries supported
- specify
Database Roots
- persistent objects with a well-known name
- class
os_database_root- root name as
char * - pointer to object as
void *
- root name as
Objectivity/DB
Key Features
- Logical and physical pages
- non-destructive manipulation
- simple rollback/commit
- Relationships
- bidirectional relationship outside of class
- LINQ
- Parallel Query Engine
- Graph Navigator
- Core implemented in C++
- Language support
- C++
- C#
- Java
- Smaltalk
- Python
- SQL++
- XML
- Platform support
- Windows
- Linux, Altix
- UNIX: Solaris, HP-UX, IBM RS/6000
- OS X
- 32-bit and 64-bit
Architecture
- Client/Server
- Lock Servers
- Data Servers
- Query Servers (Parallel Query Engine)
- task splitter
- multiple query server scanning portions of data in parallel
- Client-side Objectivity Kernel
Federation
Federation > Database > Container > Objects
- A Federation contains several DBs.
- A DB contains several Containers.
- A Container contains several Objects.
| Logical | Physical |
|---|---|
| Federation | File |
| Database | Files |
| Container | Pages |
| Objects | Slots |
- Federated DB contains one or more DBs
- A DB file can be copied to other machine
Databases
- Databases are files
- contain objects in container
- up to 65530 databases per federation
- a database holds up to 65530 containers
- can be moved or copied to any disk/machine
- can be marked read-only or taken off-line
Containers
- Collections of objects in DB
- contained objects can be of any size or type
- can grow up to 65530 pages
- Useful for logical partitions
- by owner
- by attribute
- by time
- …
Pages
- Logical and Physical
- logical page is permament part of object ID (OID)
- physical page is where the page is put in the file
- Different age sizes possible
- Unit of transfer from disk or server
- Unit of locking
- one writer
- multiple readers
Logical and Physical Pages
- When page is modified
- new page is written to container
- old page is kept
- journal file is written
- containing current page map
- When a transaction commits
- page map is updated and written to disk
- old page is freed (for reuse)
- journal file is truncated
- lock removed on lock server
- If a transaction aborts
- new page is freed (for reuse)
- lock is removed from server
Persistent Object Model
- Language independent
- Persistence by inheritance
- Base types
- numeric: sbyte, short, int, long, byte, ushort, uint, ulong, float, double
- string: ASCII (8-bit), UTF8, UTF16
- boolean
- date/time
- Complex types
- embedded: stored as part of parent object
- referece: parent object stores object identifier
- enumeration
- arrays (fixed and variable-length)
- Relationships
- Collections
Relationships
- between objects declared in classes
- unary and binary
- to-one and to-many
- Storage and management of relationships
- inline
- non-inline
- binary associations represented as separate construct internally
- Consistency of relationships
- referential integrity
- inverse relationship of binary relationship is updated automatically
- objects are removed from all relationships when deleted
Non-Inline Relationships (default)
- Each object with relationships has a default relationship array
- all non-inline relationships are stored in that array
- Each relationship in the array is identified by
- relationship name (id, not string)
- object id (ODI) of related object
- Objectivity traverses relationships until it locates the desired relationship
- array is like part of an adjacent matrix
Inline Relationships
- To-one inline relationships: embedded as fields of an object
- To-many inline relationships: placed in their own array
Deletion and Lock Propagation
- Relationshis can have semantics
- Deletion propagation
- if object is deleted all associated objects are deleted
- Lock propagation
- if object is locked all associated objects are locked
- Developer specifies operation and direction of propagation
Copy and Versioning Behaviour
- Policies define what happens to object relationships when a copy or a new version of an object is made
- copy: old an new object associated with same objects
- drop: only old object is associated with other objects
- move: only new object is associated with other objects
Domain Classes
- .NET partial classes to separate app and persistence code
- Persistence by inheritance
- both partial classes inherit form
ReferenceableObject
- both partial classes inherit form
- Persistence code class
- defines schema class and attributes
- functionality to create and dispose objects
- properties for attributes defined by schema
- proxy cache for each relationship
- helper and utility functionality
- App code class contains user-defined code
Connection, Sessions and Threads
- Static funtions for startup, shutdown and connection
- One connection to federation per application process
- Seesions
- manage resources (cache, transaction state …)
- one or many per thread or
- one shared by many threads
- Cache
- remains intact through commits and checkpoints
- flushed if transaction aborted
Persistent Collections
- Built-in persistent collections: sets, lists and maps
- automatically persistent (when created)
- conform to
System.Collections.Genericinterface
- Types of persistent collections
- ordered vs. unordered
- scalable vs.non-scalabse
Iterators
- Iterators are transient
- provide access to persistent objects
- Predicates can be supplied to iterators
- no (or less)
ifs in loop
- no (or less)
- Not an efficient method for looking up objects
- predicates evaluated on client (unless index is available)
- can be improved with indexes and scoping
- Result is not built entirely before it is returned
- clients can start process result (instead of getting blockes)
- sorting of result is not possible
Scope Names
- Generalization of DB roots
- Unique name
- Possible on each storage level
- container
- database
- federation
Retrieving Objects
-Scope names
- Creating links (and following them)
- Individual and group lookup
- keys
- iteratos
- Parallel query
- Parallel Query Engine
- divides query among several servers
- Content-based filtering
- predicate-query language
- used to follow to-many relationships
- used in parallel queries
LINQ Overview
- Part of .NEW (
System.Linq) - add native query capabilities to .NET languages
- Standard query operators defined by class
Enumerable - Language extensions are translated into method calls
- Static safety
Graph Databases
- Domain specific solution
- for a group of problems
- a kind of solution for a kind of problems
- Technology models (describe the world):
- Key-Value Map
- Relational Model
- OO Model
- Mapping between models
- There is no generic model for all domains
Social Network Analysis
- People are connected to each other
- Networks may be represented as graphs
- Nodes: peoples
- Edges: relationships
- Social Network Analysis to gather information
Graphs
- Nodes and Edges may have attributes
- Often key-value pairs
- Graph algorithms can compute different values
- Connections vary:
- Uni- / Bidirectional connections
- Nodes with single / multiple connections
- Multiple connections with different attribute
- Explicit / implicit connections
- Transient / long lasting connections
- One-time / repeated connections
- regular / irregular connections
Graph Metrics
Path Lengths
Node Properties
- Degree Centrality
- The number of direct connections a node has
- Betweenness Centrality (Bridge)
- A node is between two important nodes
- has great influence what flows in the network
- Closeness Centrality
- A node has the shortest path to all others
- good position to monitor information flow in network
Network Structure Properties
- Network Centralization
- Dominated by one or few nodes
- (single) point of failure
- Density/Cohesion
- Proposition of direct connections relative to all possible connections
- Distance (Small World)
- Minimum numbers of edges needed to connect two particular nodes
- Clustering Coefficients
- Likelihood that two associates of a node are also associates to each other
- ‘cliquishness’
General Model
- Common representation
- Uniform graph representation
- needed to apply algorithms
- Always 2 core identities connected by action
- e.g.
- connect 2 authors that worked on same publication
- or connect publications that have the same author
Graph Database Implementations
- API
- Support for CRUD
- High-level operations for graph traversals
- Sometimes graph algorithms part of DB
- ACID
- Scalable
- Examples:
- Objectivity InfiniteGraph
- Neo4j
- OrientDB
InfiniteGraph (Objectivity)
- Graph library on top of Objectivity/DB
- Distributed graph DB
- Classes for Vertex and Edge are predefined and persistent capable
BaseVertexBaseEdge
- DB API extended with graph methods
- Traversing/Querying the graph: Navigator Engine
- Put the current path from here
- Follow path from here
- if yes: which path to follow
- Interfaces for Navigator Engine
- Path Guide (path to go next)
- Path Qualifier (terminate current path?)
- Result Qualifier (put path in result set?)
- Result handler is called after navigation on result set
- Properties of the Navigator Engine
- not declarative
- interfaces to implement
- some predefined queries available
Neo4j
-
Open Source DB for Java
-
Distinction between marking transaction and finishing (committing)
-
Only generic node class available
- Generic Node (
GraphDatabaseService.createNode()) - Generic Edge (
Node.createRelationshipTo(...)) - set properties as key-values (
setProperty(...))
- Generic Node (
-
Generic nodes can be integrated into Java classes (different use of nodes)
-
Graph Traversal
- using fluent interface (chaining method calls)
- Provides special methods for
breadthFirst()ordepthFirst()evaluator(Evaluator)- Continue from here?
- Put node/path in result?
- Relationships to follow (
relationships(RelationShipType, Direction))
- all these methods return a
TraversalDescriptionobject, supports chaining - evaluator looks at a Path object
- decides if it should be in the result
- decides if the traverser should continue actual path
- Method to be implemented:
Evaluation evaluate(Path path) - return value:
EXCLUDE_AND_CONTINUEEXCLUDE_AND_PRUNEINCLUDE_AND_CONTINUEINCLUDE_AND_PRUNE
- Iterator over result set
- Not declarative
-
Graph algorithms
- find all paths between two nodes
- Dijktra-based cheapest path
- Paths with given length
- Shortest paths
-
REST API
- Management (CRUD) of nodes and edges
- GET/POST
- JSON in-/output
- Graph traversals
- Graph algorithms
- Management (CRUD) of nodes and edges
-
Query language: Cypher
- Declarative
- pattern matching
- supports update operations
- ASCII art
- try it online
Comparison between InfiniteGraph and Neo4j
| Infinite Graph (Objectivity) | Neo4j |
|---|---|
| no database orthogonality | partly data-type orthogonality (RelationshipTypes need to be implemented) |
| independence (persistence orthogonality) | (no) independence (persistence orthogonality) |
Extend BaseVertex and BaseEdge | Only generic nodes and edges available |
| Navigation with implementation of interfaces (Qualifiers) | Navigation with fluent interface (chaining) |
| Navigation not declarative | Navigation not declarative |
| Part of Objectivity (object database) | Some graph algorithms included |
| REST API: CRUD, JSON, algorithms | |
| Cypher: ASCII Art, declarative query language |
Version Models
- Various models proposed
- temporal DBs
- CAD/CAM
- SW configuration and engineering environments
- Some object-oriented DBs provide versioning
Comparison:
- Version Control Systems: unstructured data
- Versioning DBs: structured data
Versioned Object
- Concept with number of states
- Different levels of granularity
- entire files
- tuples of relation
- attributes of a class
- objects in OOP system
- Each version is a possible representation of the object
- corresponding directly to one of its states
Version Organsiations
- Relations between version
- not related (set)
- linerar versioning (time, list)
- trees (branches)
- DAG (merging)
References
- Specific reference
- references single version of object directly
- Generic reference
- references entire object
- has to be dereferenced to a version when traversed
- default version
- it’s not always clear which version is the default one (e.g. DAG)
Storage Strategies
- Representing versions at physical level
- store complete versions of objects
- store changes (deltas) between versions
- Delta-based approaches
- forward or backward deltas
- state-based or operation-based delta
- Different strategies have different perfomance
- storage vs. retrieval
- space vs. time
- …
Operation and Interaction Models
- Operations
- Control evolution of versions (of single objects)
- create new version
- branch a parallel version
- merge two parallel versions
- delete a version
- Interaction or transactions models
- working with complex objects and object graphs
- automatic versioning transparent to user
- library model uses check-out and check-in operations
- long running and nested transactions
Queries and Configurations
- additional constraint to seletc correct representations (versions)
- various implementations
- configurator evaluates rules against versioned objects
- declarative queries express constraints in extended language
- logical (based on feature logic)
- Dereferencing of generic references
- query evaluator needs to select specific version
- access for parallel versions
- access for sequencial versions
Temporal Databases
- one of the first application domains for version models
- manage different time-dependent data
- field of research
- numerous approaches
- mostly based on relational DBs
Time in Databases
- does time stored in a DB represent
- time in the domain (e.g. event schedule)?
- time of DB operation (e.g. insertion, update)?
- can the time be arbitrary modified?
- is the time value provided by app or DB?
- …
- different types of time to characterise temporal data
- Transaction, Registration or Physical time
- transaction or registration time
- captures when values were stored in DB
AS-OFoperation
- Valid or logical time
- real-world time
- used to express when values existed in real world
WHENoperation
- Bitemporal: combination of physical and logical time
- User-defined time
- all other aspects of time
- Transaction, Registration or Physical time
Classification of Temporal Databases
- Static or snapshot DB
- conventional DB
- does not manage temporal data
- supports only one single version
- if value is updated, previous value is lost
- Static roll-back DB
- like version control system (more or less)
- changes can be made only on actual version
- errors in older versions can’t be fixed
- keeps track of transaction time
- supports
AS-OFoperation - no way to correct an error
- space or computation overhead (destructive vs. non-destructive)
- Historical DB
- keeps track of valid time
- supports
WHEN - changes can be made to previous values
- Temporal DB
- bi-temporal
- keept track of transaction and valid time
- supports
AS-OFandWHENoperations
- Spatio-Temporal DB
- DB for moving objects
- continuous update of location
- uncertainty of location value
Querying Moving Objects with Uncertainity
-
Point Queries
- operators over singel trajectory
Where_At(trajectory T, time t): expected location on routeTat timetWhen_At(trajectory T, location l): times object expected to be at locationlonT
- operators over singel trajectory
-
Spatio-Temporal Range Queries
- set of 6 boolean predicates
- give qualitative description of relative position
-
location changes continuously: condition satisfied sometime or always within
-
due to uncerainty: condition satisfied possibly or definitely at point
-
possibly: trajectory with uncretainity
-
sometime: don’t care about time
Leads to 8 possible operators
Possibly_Sometime_Inside( T, R, tb te)Sometime_Possibly_Inside ( T, R, tb, te)Possibly_Always_Inside( T, R, tb, te)Always_Possibly_Inside( T, R, tb, te)Definitely_Always_Inside( T, R, tb, te)Always_Definitely_Inside( T, R, tb, te)Definitely_Sometime_Inside( T, R, tb, te)Sometime_Definitely_Inside( T, R, tb, te)
Some of them are semantically equivalent
Representing Temporal Data
- Tuple Versioning
- tuple is extended with attribute for temporal dimension
- can be realised without violating relational first normal form
Example:
| Employee | Office | Salary | TS | TE |
|---|---|---|---|---|
| Anne | A12 | 5500 | 2000 | now |
| Bob | B 34 | 4000 | 2002 | 2003 |
| Bob | B 34 | 5500 | 2003 | now |
| Charles | C 56 | 6700 | 1995 | 2000 |
| Charles | C 56 | 7500 | 2000 | 2006 |
| Charles | C 56 | 7000 | 2006 | now |
| Denise | B 34 | 3000 | 1990 | 1995 |
| Denise | B 34 | 5300 | 1995 | 2002 |
- Attribute Versioning
- each attribute is extended with temporal information
- requires non-first normal form relational systems
Example:
| Employee | Office | Salary |
|---|---|---|
| Anne | A12 | (5500, 2000, now) |
| Bob | B 34 | (4000, 2002, 2003) (5500, 2003, now) |
| Charles | C 56 | (6700, 1995, 2000) (7500, 2000, 2006) (7000, 2006, now) |
| Denise | B 34 | (3000, 1990, 1995) (5300, 1995, 2002) |
Conceptual and Data Models
- Early models: extend relational of E/R model
- Bitemporal Conceptual Data Model (BCDM)
- tuple versioning
- using 4 additional columns per tuple
- transation time and valid time
- special ‘until changed’ and ‘now’ values indicate if a tuple is current
- query language TSQL2
- extension of SQL
- introduces
VALIDTIMEandWHENclause - integrated into SQL3 as SQL/Temporal
Homogeneous and Heterogenous Models
- homogenous if temporal domain does not vary from one attribute to another
- all models that use tuple versioning are homogenous
- heterogenous if attributes of a tuple associated to different times
Storage Models
- Temporal relation as 3-dimensional data structure
- sequence of relations
- data cube
- implemented using a two level store structure
- primary store contains current versions
- satisfy all non-temporal queries
- history store hold in remaining history versions
- primary store contains current versions
- traditional access methods cannot be used in such a storage model
- Two-level Storage Structures
- Reverse Chaining
- Accession Lists
- Clustering
- Stacked Versions
Engineering Databases
- Engineering application domains
- Computer-Aided Design (CAD)
- Computer-Aided Manufacturing (CAM)
- support development and maintenance of products
- Requirements
- data structures
- concurrency control concepts
- define and manage complex (and hierarchical) design objects
- versionen support for complex objects
- iterative development
- alternatives and trial-and-error experiments
- 2-dimensional version models
- linear revision dimension
- non-sequential variation dimension
Design Space Version Model
- Modeling primitives
- component hierarchies (is-a-part-of)
- version histories (is-a-kind-of, is-derved-from)
- configurations combine hierarchies and version histories
Software Configuration Systems
- Developed for SW development
- SW Configuration Management (SCM)
- SW Engineering Environments (SEE)
- manage product directly
- fully automting process of building final product
- built around source files and program modules
- reference and dependencies management complex
- hidden inside source code files
Product Space Representation
- Data model with type relationships
- composition tree with files as leaves
- dependencies are sepresented within tree
- build information can be computed from composition and dependency relationships
- Without spanning tree
- all files of one module are summarised as one object
- only source dependencies are represented
- directly corresponds to logical structure
Version Space
- Version model defines how objects are versioned
- versioned object is container for set of object version
- common properties shared by all versions (invariants)
- differences (deltas) between versions
- symmetric deltas
- directed deltas (changes)
- Definition of version set
- extentional versioning enumerates all member of version set
- intentional versioning uses predicate defining version set members
- Evolution
- revisions: track of history
- variants: alternatives
- can be used for cooperation and collaboration
Version Space Representation
- One-level representation
- Successor relationship (Sequence)
- Branch (Tree) and Merge (DAG)
- Two-level representation
- Revision
- Variants
Indexing
Make OODBs faster and more performant
- Compare OOP model to Relational model
Main differences between OOP and Relational model:
- inheritance (is-a)
- multitype attributes (sets, collections)
- First normal form in Relational Databases disallows mutlivalued attributes (collections) in a field
- dereferencing a path of pointers/references (traversing the object graph)
OODB systems can be faster when using additional information that a RDBMSs doesn’t have
Different approaches to:
- Mapping (ORM)
- Physically represent data differently (eg. Objectivity)
- Use additional (meta-) data but keep the representation of the data
- secondary datastructures
- index structures
- Group record: pages, clusters …
Type Hierarchy Indexing
Key- vs Type-Grouping
- Key-Grouping
- build index along the actual attribute value
- as -trees
- additional information about typing and sub-typing in the leafs
- Type-Grouping
- index built along typing information
- values are secondary datastructure
Extent and Full Extent
- Extent: all objects of a given class (without sub-classes)
- Full Extent: all objects of a given class and it’s sub-classes
Single Class Index (SC-Index)
- Index construction for attribute of a type t
- incorporate only direct instances of a particular type in index
- construct search structure for all types in sub-hierarchy of t
- search data structures (called SC-Index components)
- Evaluator needs to traverse all components referenced by query
- Usually implemented using -trees
- Type-Grouping
Class Hierarchy Index (CH-Index)
- One search structure for all objects of all types of indexed hierarchy
- One index on the common attribute for all classes of a inheritance graph
- Leaf node consists of
- key-value
- key directory
- contains an entry for each class that has instances with the key-value in the indexed attribute
- entry for a class consist of class identifier and offset for list of OIDs in index record
- number of elements in list of OIDs (for each class in the inheritance graph)
- list of OIDs
- Evaluator scans through -tree once
- selects OIDs f types referenced by query
- discards other OIDs
- Point queries perform good
- Range queries depend on number of referenced types
- good when queries aim at indexed type and all sub-types
- bad if only few types of indexed hierarchy hit by query
- Key-grouping structure
H-Tree
-
Set of nested -trees
-
Combining class hierarchy with SC-Index
-
Nesting reflects indexed type hierarchy
- each H-tree component is nested with H-trees of immediate sub-types
- H-tree index for attribute of inheritance sub-graph is H-tree hierarchy nested according to super-type-sub-type relation
-
Avoids full scans of each B-tree component when several types queried
-
Single type look-up: don’t search nested trees
-
Type hierarchy look-up: traverse nested trees
-
Type-grouping structure
Class Division Index (CD-Index)
- Compromise between
- indexing for each type
- indexing extent for each type
- Specific family of type sets for indexed hierarchy
- Look at all possible combinations of full extends for all types
- Combine parts of sub-type hierarchies to use one index structure (like SC-index)
- Each typeset managed with search data structure
- Parameters q and r give bounds
- q: number of index structures needed to build a type extent
- r: number of times a type set is managed redundantly or replicated
- big q: slow queries
- big r: slow updates
- Multiple index structures need to be accessed for a query
- trade-off between:
- number of index structures to access for a query
- number of index structures to maintain
- trade-off between:
- Type-grouping structure
Multi-Key Type Index (MT-Index)
- Multi-Dimensional indexing (locality)
- Type information as additional attribute available
- Compromise between
- type grouping
- key grouping
- Type membership as additional object attribute
- symmetrical indexing of object types and attributes
- indexing of more than one attribute with single search structure
- Linearization
- Key-grouping structure (type is handled as an attribute)
Aggregation Path Indexing
- Backward queries
- without full object tree traverses
- Forward queries
- without retrieving intermediate objects
- less hops to get to objects referenced over seversl levels
- shortcut forward
Nested Index (NX)
- Direct association between
- an ending object and
- corresponding starting objects along a path
- Bypassing intermediate objects
- Only allows backwards traversals of full path
- Equivalent to backward traversal in ASR canonical
- A Nested Index NX(P) for path P with length 1 is equivalent to a Multi-Index MX(P) for the same path
- Updating index structure is expensive
Path Index (PX)
- Records all sub-paths leading to an ending object
- Predicates can be evaluated on all classes along the path
- Equivalent to backwards traversal of right-complete ASR
- A Path-Index PX(P) for path P with length 1 is equivalent to Multi-Index MX(P) an a Nested Index NX(P) for the same path
- Updating index structure better than with NX
Join-Index (JX)
- Originally for optimization of joins in Relational DBs
- Consists of a set of binary join indexes (Slides p. 33)
- Forward references are also indexed
- Cost compared to MX doubled
Multi-Index (MX)
- Like Join-Indexes in Relational DBs
- Divide path (of arbitrary length) into sub-paths
- sub-paths have length 1
- index maintained over sub-paths
- Query evaluation
- concatenating n index edges requires n index scans
- supports backward traversals and queries
- no forward traversals and queries
- Each index enty is represented as a pair
- A key-value
- set of OIDs of objects holding this key-value (for indexed attribute)
- Updates cheap
- Complex queries expensive (hop over nodes)
- each reference in object has index structure for backward references
Access Support Relations (ASR)
- Given a path create 4 index structures that support all desired queries (Nested Index, Path Index, Multi-Index)
- Canonical representation
- Full representation
- Left representation
- Right representation
- Related to Relational DB Joins: canonical is like regular join in SQL
- ASR Compositions Index Graph
- Queries that do not traverse the path at either endpoint can’t be answered efficiently
- Aggregation path can be split in sub-paths (partitions)
- Set of partions: decompositions of an ASR
Overview: Aggregation Path Indexing
- Nested Index and Path Index implemented using
- trees or
- hash tables
Collection Operations
- For: sets, bags, lists, arrays
- new modelling features, enhanced expressiveness
- increased complexity of indexing and query optimisation
- OQL provides constructors and operators for collections
Signature Files
- Index construction for a multi-valued property of a type
- Query over multi-valued properties
- Compute signatures for attribute values, elements …
- Use mathematical operation
- Super-set, sub-set …
- ‘actual drop’: true positive
- ‘false drop’: false positive
The OM Data Model
- Extended Entity-Relationship model
- for OOP data management
- special features
- difference between typing and classification
- types (model):
- names
- attributes
- behaviour
- relationships
- objects: attributes and methods
- multiple inheritance, multiple instantiation (gain/lose roles), multiple classification
- collections as first-class concepts
- binary associations as first-class concepts
- constraints for integrity, classification and evolution
- data definition, manipulation and query language (OML)
Typing and Classification
| Typing | Classification |
|---|---|
| static | dynamic |
| representation of entities | roles of entities |
| defines format of data values | defines semantic groupings as collections of values |
| defines operations | defines constraits among collection |
| defines inheritance properties | Collections: member type |
| ‘Java’ classes | |
| multiple inheritance/instantiation |
- better understanding of issues
- important to recognise the two concepts
- Reduces complexity of type graphs
- no need to introduce subtypes to represent each classification
- Rich classification structures
- Support for relationships between objects
- accociation over collections instead embedded in objects
- Integration of:
- Database
- Programming Languages
- Collections
- semantic groupings of objects
- Member types of collections
- constrain membership in a collection
- can define a view of object accessed in context of collection
- Object evolution
- objects can gain/loose roles by being added or deleted form collections
- type change not always required (???)
OM Data Model Layers
-
OM distinguishes
- typing from
- classification
-
Type-layer
- object representation
- objects: type units
- can gain and lose types dynamically: dressing and stripping
- multiple inheritance
- multiple instantiation
- objects can have types from parallel inheritance hierarchies
- objects can have types that are completely unrelated
- object representation
-
Classification-layer
- based on types from type layer
- semantic groupings: collections
- membership constrained by type
- associations to link objects together
- kinds and roles
- constraints
- subcollections and supercollections
- cardinality to describe associations
- evolution constraints
- …
- multiple classification
- collections and associations
-
Associations can be nested
- model n-ary relationships
- clearer semantics
- allow uniform query language
-
Things that exist
- types
- values for attributes
-
Collection is not just contains objects
- relationship to objects
- name
- constraint (subset relation)
- joint
- disjoint
- associations
- collection to pairs
-
e.g: A person becomming a friend or an enemy doesn’t change (or add/remove) any properties of a person type
-
Objects can gain state and behavior dynamically
- distinguish
- object: can refer to, identity, can be pointed to
- instance: container of values of a particular type
- distinguish
-
Relationships
-
intentional / extensional
-
Query
- Decide if something in a collection or not
- Traversing result (iterator, cursor)
-
SQL
- relationships mapped by primary-/foreign-key
selectcan be used instead ofjoinsto follow relationships- A selection query is fully specified when:
- providing a set of candidates and
- a function that takes individual candidates and returns true or false
-
OM Model queries
- Declaritive query language
- Collections are sets of candidates for queries
-
Map-Reduce
Collection Constraint
- Disjoint: XOR
- Cover: OR
- Partition: one and only one needs to be true
Associations (Relationships)
- binary relation between 2 collections
- cardinality
- tuple as type of collection
- can be nested: n-ary relationships
Object Model Language (OML)
- Declarative OOP language for OM data model
- OML Data Definition Language
- object and structured type definition
- method definition and emplementation
- collection, association and constraint definition
- OML Data Manipulation Language
- creating and updating objects
- ceate, update, delete, dress and strip operations
- OML Query Language
- expressions and functions for values of base types
- operations on objects
- access attributes
- invoke methods
- operations on collections (collection algebra)
- map-reduce
- very important operations after selection
Collection Algebra
- Operations defined for collections of OM model
- union
- intersections
- difference
- selection
- map
- takes a set of objects and applies a function on each object
- the result set has the same carinality
- reduce
- take a set of values (objects)
- return one value (object)
- flatten
- Sematics of operations depend on collection behaviour
- set theory defines semantics
- generalisation for bag, sequence and ranking
- mixing and converting collection types
Binary Collections
- All collections-operations can be applied to binary collection
- Binary collections suort additional operations
- domain and range
- not same as collection with tuple containing ‘range’ and ‘domain’
- domain and range restriction (selection)
- subtraction
- inverse
- swapping domain and range
- nest
- grouping of binary collections
- compose
- find associatd objects in DB it may be necessary to compose (join) associations
- closure
- repeatedly compose binary collection with itself
- division
- divide a binary collection with a unary collection
- domain and range